Memory Management in Linux
关于 Linux 中内存管理的部分内容学习。
Linux 内核版本:4.14.203
1. _do_fork 系统调用
1.1. vfork、fork、clone
| 系统调用 | 特点 |
|---|---|
fork |
子进程拷贝父进程的数据段、代码段;父子进程的运行次序不确定 |
vfork |
创建轻量级的进程,即线程;父子进程共享数据段;保证子进程先运行,如果子进程依赖于父进程可能会死锁 |
clone |
用于创建线程 |
1.2. Related Structure
1.2.1. task_struct
Linux 通过进程描述符(task_struct 结构体)来管理每一个进程,其中包含了一个进程所需的所有信息:
struct task_struct {
...
volatile long state; // 进程状态
...
void *stack; // 指向内核栈的指针
atomic_t usage; // 进程描述符使用计数
unsigned int flags; // 进程标记符
unsigned int ptrace;
...
unsigned int cpu;
...
// 进程的优先级信息
int prio; // 动态优先级
int static_prio; // 静态优先级
int normal_prio; // 取决于静态优先级和调度策略
unsigned int rt_priority; // 进程运行(实时)优先级
const struct sched_class *sched_class; // 调度类
struct sched_entity se; // 普通进程的调用实体
struct sched_rt_entity rt; // 实时进程的调用实体
...
unsigned int policy; // 进程调度策略
int nr_cpus_allowed;
cpumask_t cpus_allowed; // 用于控制进程可以在哪里处理器上运行
...
struct sched_info sched_info;
struct list_head tasks; // 进程链表
...
// 进程内存管理信息
struct mm_struct *mm;
struct mm_struct *active_mm;
// 终止状态
int exit_state;
int exit_code;
int exit_signal;
...
pid_t pid; // 进程标识符
pid_t tgid; // 进程组标识符
...
struct task_struct __rcu *real_parent; // 原始父进程
struct task_struct __rcu *parent; // 当前的父进程
struct list_head children; // 子进程链表
struct list_head sibling; // 兄弟进程链表
struct task_struct *group_leader; // 所在进程组的领头进程
// ptrace跟踪进程标志位
struct list_head ptraced;
struct list_head ptrace_entry;
struct pid_link pids[PIDTYPE_MAX];
// 该进程的所有线程链表
struct list_head thread_group;
struct list_head thread_node;
...
u64 utime; // 进程在用户态下所经过的节拍数
u64 stime; // 进程在内核态下所经过的节拍数
...
u64 gtime; // 以节拍计数的虚拟机运行时间
struct prev_cputime prev_cputime;
...
u64 start_time; // 创建进程时间
u64 real_start_time;
// 缺页统计
unsigned long min_flt;
unsigned long maj_flt;
...
// 进程权能
const struct cred __rcu *ptracer_cred;
const struct cred __rcu *real_cred;
const struct cred __rcu *cred;
char comm[TASK_COMM_LEN]; // 各个程序名
...
struct fs_struct *fs; // 文件系统信息
struct files_struct *files; // 打开文件信息
struct nsproxy *nsproxy; // 命名空间
struct signal_struct *signal; // 进程的信号描述符
struct sighand_struct *sighand; // 进程的信号处理程序描述符
sigset_t blocked; // 被阻塞信号的掩码
sigset_t real_blocked; // 临时掩码
sigset_t saved_sigmask;
struct sigpending pending; // 挂起信号
unsigned long sas_ss_sp; // 信号处理程序备用堆栈的地址
size_t sas_ss_size; // 信号处理程序备用堆栈的大小
unsigned int sas_ss_flags; // 信号处理程序备用堆栈的标志位
...
struct seccomp seccomp;
spinlock_t alloc_lock; // 用于保护资源分配或释放的自旋锁
...
struct reclaim_state *reclaim_state; // 内存回收
struct backing_dev_info *backing_dev_info;
struct io_context *io_context; // I/O调度器所使用的信息
...
struct thread_struct thread; // 处理器特有数据
};
1.2.2. thread_info
thread_info 用于保存进程描述符中频繁访问以及需要快速访问的字段,内核依赖于 thread_info 来获取当前进程的描述符。如果编译时设置了 CONFIG_THREAD_INFO_IN_TASK 选项,内核态的进程堆栈和 thread_info 会被放到一个联合体,共用一块内存:
struct thread_info {
unsigned long flags; /* low level flags */
u32 status; /* thread synchronous flags */
};
union thread_union {
#ifndef CONFIG_THREAD_INFO_IN_TASK
struct thread_info thread_info;
#endif
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
此时线程描述符在内存区的起始处,而栈自顶向下增长。current 指针和进程描述符中的 thread_info/stack 指针都指向当前运行进程的 thread_union 的地址:
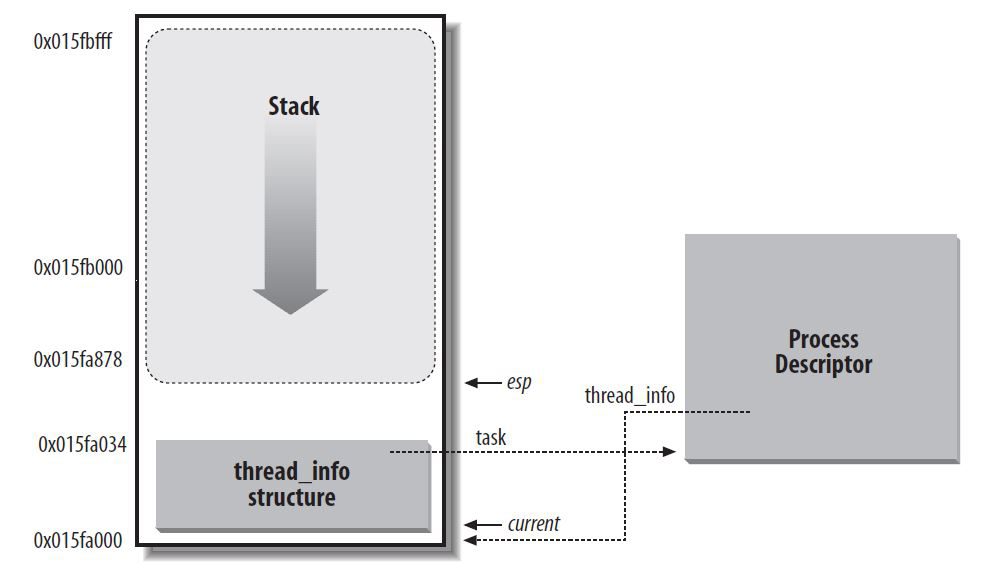
1.2.3. init_task
Linux 下有 3 个特殊的进程,idle 进程(0)、init 进程(1)和 kthreadd(2):
- idle 进程由系统自动创建,运行在内核态;其前身是系统创建的第一个进程,也是唯一一个没有通过
fork或者kernel_thread产生的进程。完成加载系统后,演变为进程调度、交换; - init 进程由 idle 通过
kernel_thread创建,在内核空间完成初始化后, 加载 init 程序,并最终进入用户空间,成为所有用户进程的先祖;其完成系统的初始化. 是系统中所有其它用户进程的祖先进程。内核启动后在用户空间中启动 init 进程,再启动其他系统进程。在系统启动完成完成后,init 将变为守护进程监视系统其他进程; - kthreadd 进程由 idle 通过
kernel_thread创建,并始终运行在内核空间, 负责所有内核线程的调度和管理;管理和调度其他内核线程kernel_thread,会循环执行一个 kthread 的函数,该函数的作用就是运行kthread_create_list全局链表中维护的 kthread,当我们调用kernel_thread创建的内核线程会被加入到此链表中,因此所有的内核线程都是直接或者间接的以 kthreadd 为父进程。
init_task 进程(0 号进程)是唯一一个通过静态分配创建的进程,宏 INIT_TASK 完成 init_task 变量中进程描述符的初始化:
#define INIT_TASK(tsk) \
{ \
INIT_TASK_TI(tsk) /* 初始化thread_info */ \
.state = 0, \
.stack = init_stack, \
.usage = ATOMIC_INIT(2), \
.flags = PF_KTHREAD, \
.prio = MAX_PRIO-20, \
.static_prio = MAX_PRIO-20, \
.normal_prio = MAX_PRIO-20, \
.policy = SCHED_NORMAL, \
.cpus_allowed = CPU_MASK_ALL, \
.nr_cpus_allowed= NR_CPUS, \
.mm = NULL, /* 初始化内存 */ \
.active_mm = &init_mm, /* 调用init_mm函数 */ \
.restart_block = { \
.fn = do_no_restart_syscall, \
}, \
.se = { \
.group_node = LIST_HEAD_INIT(tsk.se.group_node), \
}, \
.rt = { \
.run_list = LIST_HEAD_INIT(tsk.rt.run_list), \
.time_slice = RR_TIMESLICE, \
}, \
.tasks = LIST_HEAD_INIT(tsk.tasks), \
INIT_PUSHABLE_TASKS(tsk) \
INIT_CGROUP_SCHED(tsk) \
.ptraced = LIST_HEAD_INIT(tsk.ptraced), \
.ptrace_entry = LIST_HEAD_INIT(tsk.ptrace_entry), \
.real_parent = &tsk, \
.parent = &tsk, \
.children = LIST_HEAD_INIT(tsk.children), \
.sibling = LIST_HEAD_INIT(tsk.sibling), \
.group_leader = &tsk, \
RCU_POINTER_INITIALIZER(real_cred, &init_cred), \
RCU_POINTER_INITIALIZER(cred, &init_cred), \
.comm = INIT_TASK_COMM, \
.thread = INIT_THREAD, \
.fs = &init_fs, \
.files = &init_files, \
.signal = &init_signals, \
.sighand = &init_sighand, \
.nsproxy = &init_nsproxy, \
.pending = { \
.list = LIST_HEAD_INIT(tsk.pending.list), \
.signal = 0}, \
.blocked = 0, \
.alloc_lock = __SPIN_LOCK_UNLOCKED(tsk.alloc_lock), \
.journal_info = NULL, \
INIT_CPU_TIMERS(tsk) \
.pi_lock = __RAW_SPIN_LOCK_UNLOCKED(tsk.pi_lock), \
.timer_slack_ns = 50000, /* 50 usec default slack */ \
.pids = { \
[PIDTYPE_PID] = INIT_PID_LINK(PIDTYPE_PID), \
[PIDTYPE_PGID] = INIT_PID_LINK(PIDTYPE_PGID), \
[PIDTYPE_SID] = INIT_PID_LINK(PIDTYPE_SID), \
}, \
.thread_group = LIST_HEAD_INIT(tsk.thread_group), \
.thread_node = LIST_HEAD_INIT(init_signals.thread_head), \
INIT_IDS \
INIT_PERF_EVENTS(tsk) \
INIT_TRACE_IRQFLAGS \
INIT_LOCKDEP \
INIT_FTRACE_GRAPH \
INIT_TRACE_RECURSION \
INIT_TASK_RCU_PREEMPT(tsk) \
INIT_TASK_RCU_TASKS(tsk) \
INIT_CPUSET_SEQ(tsk) \
INIT_RT_MUTEXES(tsk) \
INIT_PREV_CPUTIME(tsk) \
INIT_VTIME(tsk) \
INIT_NUMA_BALANCING(tsk) \
INIT_KASAN(tsk) \
INIT_LIVEPATCH(tsk) \
INIT_TASK_SECURITY \
}
1.3. Procedure
以上三个系统调用最终都会调用 _do_fork 函数,_do_fork 中最主要是调用了 copy_process 对进程描述符进行复制:
long _do_fork(unsigned long clone_flags, // 相关标志
unsigned long stack_start, // 栈的起始地址
unsigned long stack_size, // 栈的大小
int __user *parent_tidptr, // 父进程在用户态下pid的地址
int __user *child_tidptr, // 子进程在用户态下pid的地址
unsigned long tls) // Thread Local Storage
{
struct task_struct *p; // 进程描述符
int trace = 0; // fork的种类
long nr;
if (!(clone_flags & CLONE_UNTRACED)) { // 检查是否启用ptrace
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if ((clone_flags & CSIGNAL) != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
} // 检查各项标志
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace, tls, NUMA_NO_NODE); // 复制进程信息
add_latent_entropy();
if (!IS_ERR(p)) {
struct completion vfork;
struct pid *pid;
trace_sched_process_fork(current, p);
pid = get_task_pid(p, PIDTYPE_PID); // 获取新创建进程的pid
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
if (clone_flags & CLONE_VFORK) { // 如果调用vfork
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
wake_up_new_task(p);
if (unlikely(trace))
ptrace_event_pid(trace, pid); // 完成fork后告诉ptracer
if (clone_flags & CLONE_VFORK) { // 如果调用vfork
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
} else {
nr = PTR_ERR(p);
}
return nr;
}
copy_process 中调用对进程描述符结构体中的各个成员进行了复制,其中 dup_task_struct 对进程描述符进行了复制:
static __latent_entropy struct task_struct *copy_process(
unsigned long clone_flags, //
unsigned long stack_start, // 栈的起始地址
unsigned long stack_size, // 栈的大小
int __user *child_tidptr, //
struct pid *pid, //
int trace, //
unsigned long tls, // Thread Local Storage
int node) //
{
int retval;
struct task_struct *p; // 创建进程描述符指针
// 检查各项标志
...
retval = -ENOMEM;
p = dup_task_struct(current, node); // 复制当前的进程描述符
if (!p)
goto fork_out;
p->set_child_tid = (clone_flags & CLONE_CHILD_SETTID) ? child_tidptr : NULL;
p->clear_child_tid = (clone_flags & CLONE_CHILD_CLEARTID) ? child_tidptr : NULL;
ftrace_graph_init_task(p);
rt_mutex_init_task(p); // 初始化互斥变量
...
retval = -EAGAIN;
if (atomic_read(&p->real_cred->user->processes) >=
task_rlimit(p, RLIMIT_NPROC)) { // 检查用户的进程数是否超过限制
if (p->real_cred->user != INIT_USER &&
!capable(CAP_SYS_RESOURCE) && !capable(CAP_SYS_ADMIN)) // 检查用户权限
goto bad_fork_free;
}
current->flags &= ~PF_NPROC_EXCEEDED;
retval = copy_creds(p, clone_flags);
if (retval < 0)
goto bad_fork_free;
retval = -EAGAIN;
if (nr_threads >= max_threads) // 检查进程数是否超过max_threads,由内存大小决定
goto bad_fork_cleanup_count;
delayacct_tsk_init(p);
p->flags &= ~(PF_SUPERPRIV | PF_WQ_WORKER | PF_IDLE);
p->flags |= PF_FORKNOEXEC;
INIT_LIST_HEAD(&p->children);
INIT_LIST_HEAD(&p->sibling);
rcu_copy_process(p);
p->vfork_done = NULL;
spin_lock_init(&p->alloc_lock); // 初始化自旋锁
init_sigpending(&p->pending); // 初始化挂起信号
p->utime = p->stime = p->gtime = 0;
...
prev_cputime_init(&p->prev_cputime); // 初始化CPU定时器
...
retval = sched_fork(clone_flags, p); // 对新进程的数据结构进行初始化,并启动进程
if (retval)
goto bad_fork_cleanup_policy;
retval = perf_event_init_task(p);
if (retval)
goto bad_fork_cleanup_policy;
retval = audit_alloc(p);
if (retval)
goto bad_fork_cleanup_perf;
// 复制所有进程信息,包括文件系统、信号处理函数、信号、内存管理等
shm_init_task(p);
retval = security_task_alloc(p, clone_flags);
if (retval)
goto bad_fork_cleanup_audit;
retval = copy_semundo(clone_flags, p);
if (retval)
goto bad_fork_cleanup_security;
retval = copy_files(clone_flags, p);
if (retval)
goto bad_fork_cleanup_semundo;
retval = copy_fs(clone_flags, p);
if (retval)
goto bad_fork_cleanup_files;
retval = copy_sighand(clone_flags, p);
if (retval)
goto bad_fork_cleanup_fs;
retval = copy_signal(clone_flags, p);
if (retval)
goto bad_fork_cleanup_sighand;
retval = copy_mm(clone_flags, p); // 复制内存信息
if (retval)
goto bad_fork_cleanup_signal;
retval = copy_namespaces(clone_flags, p);
if (retval)
goto bad_fork_cleanup_mm;
retval = copy_io(clone_flags, p);
if (retval)
goto bad_fork_cleanup_namespaces;
retval = copy_thread_tls(clone_flags, stack_start, stack_size, p, tls); // 初始化子进程的内核栈
if (retval)
goto bad_fork_cleanup_io;
if (pid != &init_struct_pid) {
pid = alloc_pid(p->nsproxy->pid_ns_for_children); // 为子进程分配pid
if (IS_ERR(pid)) {
retval = PTR_ERR(pid);
goto bad_fork_cleanup_thread;
}
}
...
p->pid = pid_nr(pid); // 为子进程设置pid
if (clone_flags & CLONE_THREAD) {
p->exit_signal = -1;
p->group_leader = current->group_leader;
p->tgid = current->tgid;
} else {
if (clone_flags & CLONE_PARENT)
p->exit_signal = current->group_leader->exit_signal;
else
p->exit_signal = (clone_flags & CSIGNAL);
p->group_leader = p;
p->tgid = p->pid;
}
p->nr_dirtied = 0;
p->nr_dirtied_pause = 128 >> (PAGE_SHIFT - 10);
p->dirty_paused_when = 0;
p->pdeath_signal = 0;
INIT_LIST_HEAD(&p->thread_group);
p->task_works = NULL;
...
p->start_time = ktime_get_ns(); // 初始化进程启动时间
p->real_start_time = ktime_get_boot_ns();
write_lock_irq(&tasklist_lock);
if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) { // 判断是否是父进程调用fork或clone创建线程
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
} else {
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
}
klp_copy_process(p);
spin_lock(¤t->sighand->siglock);
copy_seccomp(p); // 复制seccomp信息
recalc_sigpending();
if (signal_pending(current)) {
retval = -ERESTARTNOINTR;
goto bad_fork_cancel_cgroup;
}
if (unlikely(!(ns_of_pid(pid)->nr_hashed & PIDNS_HASH_ADDING))) {
retval = -ENOMEM;
goto bad_fork_cancel_cgroup;
}
if (likely(p->pid)) {
ptrace_init_task(p, (clone_flags & CLONE_PTRACE) || trace);
init_task_pid(p, PIDTYPE_PID, pid);
if (thread_group_leader(p)) {
init_task_pid(p, PIDTYPE_PGID, task_pgrp(current));
init_task_pid(p, PIDTYPE_SID, task_session(current));
if (is_child_reaper(pid)) {
ns_of_pid(pid)->child_reaper = p;
p->signal->flags |= SIGNAL_UNKILLABLE;
}
p->signal->leader_pid = pid;
p->signal->tty = tty_kref_get(current->signal->tty);
p->signal->has_child_subreaper = p->real_parent->signal->has_child_subreaper ||
p->real_parent->signal->is_child_subreaper;
list_add_tail(&p->sibling, &p->real_parent->children);
list_add_tail_rcu(&p->tasks, &init_task.tasks);
attach_pid(p, PIDTYPE_PGID);
attach_pid(p, PIDTYPE_SID);
__this_cpu_inc(process_counts);
} else {
current->signal->nr_threads++;
atomic_inc(¤t->signal->live);
atomic_inc(¤t->signal->sigcnt);
list_add_tail_rcu(&p->thread_group,
&p->group_leader->thread_group);
list_add_tail_rcu(&p->thread_node,
&p->signal->thread_head);
}
attach_pid(p, PIDTYPE_PID);
nr_threads++; // 线程数加1
}
total_forks++; // 总进程fork数加1
spin_unlock(¤t->sighand->siglock);
syscall_tracepoint_update(p);
write_unlock_irq(&tasklist_lock);
proc_fork_connector(p);
cgroup_post_fork(p);
cgroup_threadgroup_change_end(current);
perf_event_fork(p);
trace_task_newtask(p, clone_flags);
uprobe_copy_process(p, clone_flags);
copy_oom_score_adj(clone_flags, p);
return p; // 返回被创建的进程描述符
...
}
dup_task_struct 对进程描述符以及内核栈进行复制。完成整个 _do_fork 的操作后,子进程只有 tsk->stack 指针和父进程不同,其他部分完全相同:
static struct task_struct *dup_task_struct(struct task_struct *orig, int node)
{
struct task_struct *tsk;
unsigned long *stack;
struct vm_struct *stack_vm_area;
int err;
if (node == NUMA_NO_NODE)
node = tsk_fork_get_node(orig);
tsk = alloc_task_struct_node(node); // 分配一个进程描述符节点
if (!tsk)
return NULL;
stack = alloc_thread_stack_node(tsk, node); // 创建新的栈节点,包含进程内核栈
if (!stack)
goto free_tsk;
stack_vm_area = task_stack_vm_area(tsk);
err = arch_dup_task_struct(tsk, orig);
tsk->stack = stack; // 对栈底赋值
...
return tsk; // 返回新申请的节点
free_stack:
free_thread_stack(tsk);
free_tsk:
free_task_struct(tsk);
return NULL;
}
2. Linux 内存管理
页(结构体 page)是内核的内存管理基本单位,内存管理单元(MMU)通常以页为单位处理。内核用 page 结构体表示每个物理页,page 结构体占 40 个字节。假定系统物理页大小为 4KB,对于 4GB 物理内存,1M 个页面,故所有的页面 page 结构体共占有内存大小为 40MB,相对系统 4G,这个代价并不高:
struct page {
unsigned long flags; // 页标志符
union {
struct address_space *mapping; // 该页所在地址空间描述结构指针,用于内容为文件的页帧
...
};
union {
pgoff_t index; // 该页描述结构在地址空间page_tree中的对象索引号,即页号
...
};
union {
struct {
union {
atomic_t _mapcount; // 页映射计数
...
};
atomic_t _refcount; // 页映射计数
};
};
union {
struct list_head lru; // 最近最久未使用struct slab结构指针链表头变量
...
};
union {
unsigned long private; // 私有数据指针
...
};
void *virtual; // 页虚拟地址
};
内核把页划分在不同的区(Zone):
- 执行 DMA 操作的内存必须从
ZONE_DMA区分配; - 一般内存,既可从
ZONE_DMA,也可从ZONE_NORMAL分配,但不能同时从两个区分配。
| 区 | 描述 | 物理内存(MB) |
|---|---|---|
ZONE_DMA |
DMA 使用的页 | <16 |
ZONE_NORMAL |
可正常寻址的页 | 16~896 |
ZONE_HIGHMEM |
动态映射的页 | >896 |
2.1. 内存的分配与释放
2.1.1. 以页为单位
所有以页为单位进行连续物理内存分配的方式被称为低级页分配器:
| 页分配函数 | 描述 |
|---|---|
alloc_pages(gfp_mask, order) |
分配 2^order 个页,返回指向第一页的指针 |
alloc_pages(gfp_mask) |
分配一页,返回指向页的指针 |
__get_free_pages(gfp_mask, order) |
分配 2^order 个页,返回指向其逻辑地址的指针 |
__get_free_pages(gfp_mask) |
分配一页,返回指向其逻辑地址的指针 |
get_zeroed_page(gfp_mask) |
分配一页,并填充内容为 0,返回指向其逻辑地址的指针 |
相对应的页释放函数:
| 页释放函数 | 描述 |
|---|---|
__free_pages(page, order) |
从 page 开始,释放 2^order 个页 |
free_pages(addr, order) |
从地址 addr 开始,释放 2^order 个页 |
free_page(addr) |
释放 addr 所在的那一页 |
2.1.2. 以字节为单位
kmalloc(最终调用 __get_free_pages)、vmalloc 分配都是以字节为单位,对应有 kfree、vfree 函数:
| 分配函数 | 区域 | 连续性 | 大小 | 释放函数 | 优势 |
|---|---|---|---|---|---|
kmalloc(size, flags) |
内核空间 | 物理地址连续 | 最大值 128K-16 |
kfree(ptr) |
性能更佳 |
vmalloc(size) |
内核空间 | 虚拟地址连续 | 更大 | vfree(ptr) |
更易分配大内存 |
malloc(size) |
用户空间 | 虚拟地址连续 | 更大 | free(ptr) |
/ |
2.2. 内核页表和进程页表
页表是一种特殊的数据结构,放在系统空间的页表区,存放逻辑页与物理页帧的对应关系。每一个进程都拥有一个自己的页表,PCB 表中有指针指向页表。用固定大小的页(Page)来描述逻辑地址空间,用相同大小的页框(Frame)来描述物理内存空间,由操作系统实现从逻辑页到物理页框的页面映射,同时负责对所有页的管理和进程运行的控制。
2.2.1. 分级页表
在 32 位操作系统下,页大小为 4KB,那么页表有 1M 条目。假设每个条目占 4B,则需要 4MB 物理地址空间来存储页表本身。利用二级分页结构,可以减少页表所占用的空间。一个逻辑地址可以被分为:一个10位的页目录索引+一个10位的页表索引+一个12位的虚拟页偏移量。其转换机制如下(p1 是页目录的索引,p2 是页表偏移):
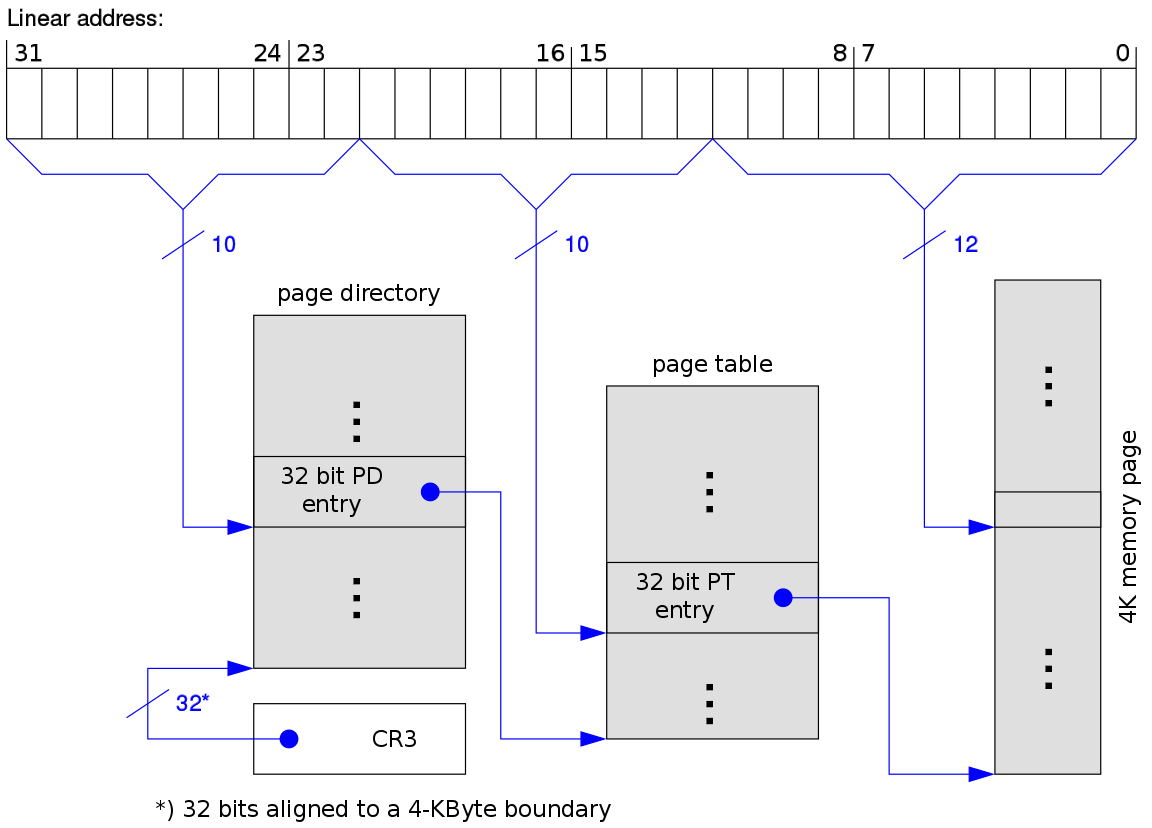
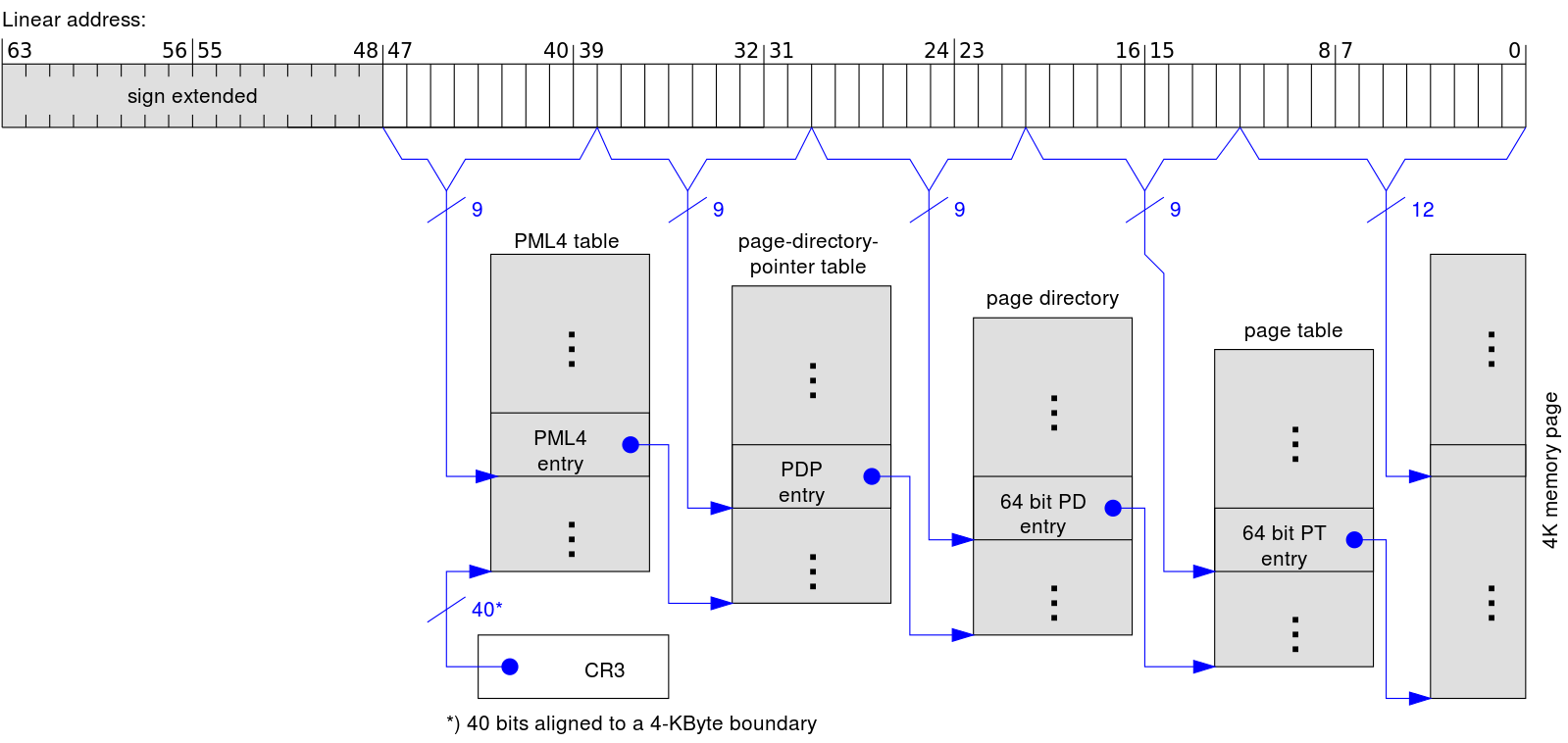
在 64 位操作系统下,页大小为 4KB,那么页表就会有 2^32M 条目。假设每个条目占 4B,则需要 16GB 物理地址空间来存储页表本身。此时利用多级页表,减少页表所占空间的效果更加明显。如下图,每个进程的 CR3 寄存器中保存着进程页目录 PGD(页全局目录,Page Global Directory)的地址,不同进程的 PGD 地址不同,在进程切换时,操作系统负责把页目录地址装入 CR3 寄存器。而整个地址翻译过程完全是由硬件完成的:
- 对于给定的线性地址,根据线性地址的前 9 位作为页上级目录项索引值,在 CR3 所指向的页全局目录中找到一个页上级目录项 PUD(Page Upper Directory);
- 找到的页上级目录项对应着页中间目录,根据线性地址的第二个 9 位作为页中间目录项索引值,在页上级目录中找到一个页中间目录项 PMD(Page Middle Directory);
- 找到的页中间目录项对应着页表,根据线性地址的第三个 9 位作为页表项索引值,在页中间目录中找到一个页表项 PTE(Page Table Entry);
- 找到的页表项中包含着一个页面的地址,线性地址的最后 12 位作为页内偏移值和找到的页确定线性地址对应的物理地址。
2.2.2. 页转换失败
在地址转换过程中,有两种情况会导致失败发生:
- 要访问的地址不存在,这通常意味着由于编程错误访问了无效的虚拟地址,操作系统必须采取某种措施来处理这种情况,一般是发送一个段错误给程序;或者要访问的页面还没有被映射进来,此时操作系统要为这个线性地址分配相应的物理页面,并更新页表;
- 要查找的页不在物理内存中,比如页已经交换出物理内存。在这种情况下需要把页从磁盘交换回物理内存。
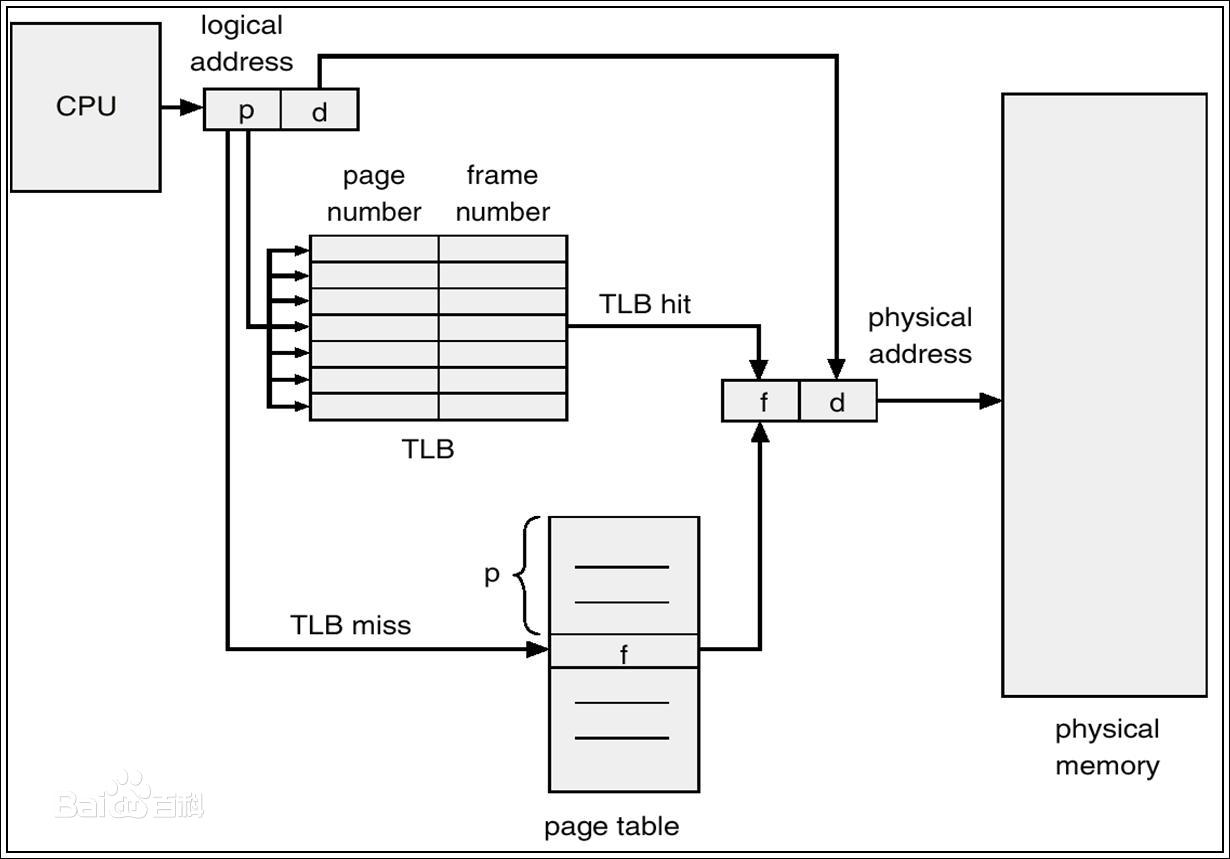
2.2.3. TLB
MMU 增加对最近使用页面的缓存,即转换后备缓冲器(TLB,Translation Lookaside Buffer)。TLB 是一种小、专用、快速的硬件缓冲,只包括页表中的一小部分条目。如果页号在 TLB 中,得到帧号,访问内存;否则从内存中的页表中得到帧号,将其存入 TLB,访问内存。
2.2.4. 内核页表
- 在古老的操作系统里面,所有进程都是共用同一物理内存空间的,这种方法会有一些问题,比如两个进程之前相互踩内存,一个进程被污染(踩内存)后,无法隔离,必须整个系统复位,才能恢复干净的环境。在这种操作系统下,进程之间无法隔离。为了解决进程之间内存隔离,提供了虚拟内存这个概念。进程看到的是虚拟内存,这根本看不到物理内存,物理内存是操作系统给它分配的,它不需要感知物理内存。对于同一程序运行起来的两个进程,它们的虚拟空间布局可能完全一样,但他们真实使用的物理内存空间则不相同,通过这种方式来实现进程之间的隔离。
- 处理器提供了虚拟内存功能,进程访问虚拟内存,CPU 执行时通过分页机制转换成物理内存访问。同一程序运行起来的两个进程,虚拟地址空间相同,但对应的物理空间是不相同的。操作系统需要给每个进程设置一份页表,在进程调度过程中,上下文切换阶段会做页表的切换。每个进程的页表都是由操作系统来管理的。每个进程的页表管理的空间包含用户态和内核态空间,所有进程内核态空间到物理地址空间是相同的。
- 在使用虚拟地址空间的 Linux 操作系统上,每一个进程都工作在一个 4G 的地址空间上,其中 0~3G 是应用进程可以访问的用户地址空间,是这个进程独有的,其他进程看不到也无法操作这个地址空间;3G~4G 是内核地址空间,所有进程共享这部分地址空间。由于每个进程都有 3G 的私有进程空间,所以系统的物理内存无法对这些地址空间进行一一映射,因此内核需要一种机制,把进程地址空间映射到物理内存上。当一个进程请求访问内存时,操作系统通过存储在内核中的进程页表把这个虚拟地址映射到物理地址,如果还没有为这个地址建立页表项,那么操作系统就为这个访问的地址建立页表项。最基本的映射单位是页,对应的是页表项 PTE。页表项和物理地址是多对一的关系,即多个页表项可以对应一个物理页面,因而支持共享内存的实现。
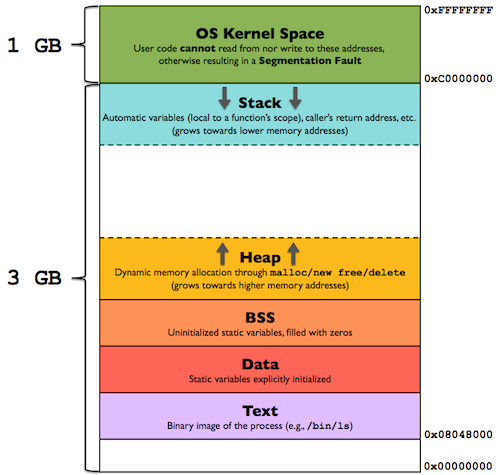
2.2.4.1. Details
- Linux 的每个进程都有单独的页表,其中内核线程使用的是内核的页表。对于普通的进程来说,都有一个叫做
mm_struct的结构体,它的成员pgd会指向内存中这个进程对应的页表。这个页表中的每一项(不是所有页表项都有效)会描述整个虚拟内存空间。Linux 用户态只能访问低于 0xC0000000(PAGE_OFFSET)的内存,高于它的内存属于内核空间地址; - 对于普通进程来说,内核页表只是进程页表的一部分,它不是单独的一个东西。Linux 内核是为了服务于用户态,而正在运行的程序陷入内核态基本手段包括中断、系统调用。当 CPU 进入内核态之后,CPU 访问内存地址还是要通过虚拟地址来访问的。此时访问虚拟地址就是通过被打断的进程的页表项才能找到对应物理地址;
- 主内核页表其实在刚开机的时候就已经初始化好了,在内核中其实就是一段内存,存放在主内核页全局目录
init_mm.pgd(swapper_pg_dir)中,硬件并不直接使用。这个地址里的每一项会描述 1M 的内存。每个用户态进程创建的时候,内核都会将这个页表复制到进程的页表中; - 内核页表由内核自己维护并更新,在 vmalloc 区发生页错误时,将内核页表同步到进程页表中。
- 在 32 位系统中,内核页表主要包含线性映射区、vmalloc 区两部分。其中,线性映射区即通过
TASK_SIZE偏移进行映射的区域(0-896M),映射对应的虚拟地址区域为TASK_SIZE~TASK_SIZE+896M。这部分区域在内核初始化时就已经完成映射,并创建好相应的页表,即这部分虚拟内存区域不会发生页错误;vmalloc 区为896M~896M+128M,这部分区域用于映射高端内存,有三种映射方式:vmalloc、固定、临时; - 以最常使用的 vmalloc 为例,这部分区域对应的线性地址在内核使用 vmalloc 分配内存时,其实就已经分配了相应的物理内存,并做了相应的映射,建立了相应的页表项,但相关页表项仅写入了内核页表,并没有实时更新到进程页表中。内核在这里使用了延迟更新的策略,将进程页表真正更新推迟到第一次访问相关线性地址,在页错误的处理流程中进行进程页表的更新。
- 在 32 位系统中,内核页表主要包含线性映射区、vmalloc 区两部分。其中,线性映射区即通过
2.2.4.1.1. Analysis
__do_page_fault 函数用于对页错误的处理,其中调用 vmalloc_fault 对 vmalloc 区的页错误进行处理:
static noinline void
__do_page_fault(struct pt_regs *regs, unsigned long error_code,
unsigned long address) // 缺页异常主处理函数
{
struct vm_area_struct *vma;
struct task_struct *tsk;
struct mm_struct *mm;
int fault, major = 0;
unsigned int flags = FAULT_FLAG_ALLOW_RETRY | FAULT_FLAG_KILLABLE;
u32 pkey;
tsk = current; // 获取当前进程描述符
mm = tsk->mm; // 获取进程的内存管理结构体
prefetchw(&mm->mmap_sem);
if (unlikely(kmmio_fault(regs, address))) // MMIO不应该发生缺页,通常会调用ioremap到vmalloc区再进行访问
return;
if (unlikely(fault_in_kernel_space(address))) { // 缺页地址发生在内核空间,也有可能是用户态访问了内核空间的地址
if (!(error_code & (X86_PF_RSVD | X86_PF_USER | X86_PF_PROT))) {
if (vmalloc_fault(address) >= 0) // 检查发生缺页的地址是否在vmalloc区
return;
}
if (spurious_fault(error_code, address)) // 检查是否因为TLB的延迟flush导致产生假的缺页错误
return;
if (kprobes_fault(regs))
return;
bad_area_nosemaphore(regs, error_code, address, NULL); // 内核态的缺页异常只发生在vmalloc区,而前面已经处理过vmalloc区的缺页异常,那可能就是内核异常
return;
}
...
// 开中断来缩短因为缺页异常导致的关中断时长
if (user_mode(regs)) {
local_irq_enable();
error_code |= X86_PF_USER;
flags |= FAULT_FLAG_USER;
} else {
if (regs->flags & X86_EFLAGS_IF)
local_irq_enable();
}
perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS, 1, regs, address);
if (error_code & X86_PF_WRITE)
flags |= FAULT_FLAG_WRITE;
if (error_code & X86_PF_INSTR)
flags |= FAULT_FLAG_INSTRUCTION;
if (unlikely(!down_read_trylock(&mm->mmap_sem))) {
// 缺页发生在内核上下文,这种情况下只能是位于用户态的地址空间
if (!(error_code & X86_PF_USER) &&
!search_exception_tables(regs->ip)) { // 如果缺页异常发生在内核态且没有在exception tables中查到
bad_area_nosemaphore(regs, error_code, address, NULL);
return;
}
retry:
down_read(&mm->mmap_sem);
} else {
might_sleep();
}
vma = find_vma(mm, address); // 在当前进程的地址空间中寻找发生异常的地址对应的VMA
if (unlikely(!vma)) {
bad_area(regs, error_code, address);
return;
}
if (likely(vma->vm_start <= address)) // 检查发生异常的虚拟地址是否在VMA的有效范围内
goto good_area;
if (unlikely(!(vma->vm_flags & VM_GROWSDOWN))) {
bad_area(regs, error_code, address);
return;
}
if (error_code & X86_PF_USER) {
if (unlikely(address + 65536 + 32 * sizeof(unsigned long) < regs->sp)) { // 压栈操作时,操作的地址最大的偏移为65536 + 32 * sizeof(unsigned long),超出这个范围即为非法地址
bad_area(regs, error_code, address);
return;
}
}
if (unlikely(expand_stack(vma, address))) {
bad_area(regs, error_code, address);
return;
}
// 进行到这里说明是正常的缺页异常,则请求调页并分配物理内存
good_area:
if (unlikely(access_error(error_code, vma))) {
bad_area_access_error(regs, error_code, address, vma);
return;
}
pkey = vma_pkey(vma);
fault = handle_mm_fault(vma, address, flags); // 分配物理内存,缺页异常的正常处理主函数
major |= fault & VM_FAULT_MAJOR;
if (unlikely(fault & VM_FAULT_RETRY)) {
if (flags & FAULT_FLAG_ALLOW_RETRY) {
flags &= ~FAULT_FLAG_ALLOW_RETRY;
flags |= FAULT_FLAG_TRIED;
if (!fatal_signal_pending(tsk))
goto retry;
}
if (flags & FAULT_FLAG_USER)
return;
no_context(regs, error_code, address, SIGBUS, BUS_ADRERR);
return;
}
up_read(&mm->mmap_sem);
if (unlikely(fault & VM_FAULT_ERROR)) { // 没有错误说明中断处理正常
mm_fault_error(regs, error_code, address, &pkey, fault);
return;
}
if (major) {
tsk->maj_flt++;
perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS_MAJ, 1, regs, address);
} else {
tsk->min_flt++;
perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS_MIN, 1, regs, address);
}
check_v8086_mode(regs, address, tsk); // VM86模式相关检查
}
调用 vmalloc_fault 对发生缺页错误的进程页表和内核页表进行同步:
/*
* 32-bit:
*
* Handle a fault on the vmalloc or module mapping area
*/
static noinline int vmalloc_fault(unsigned long address) // 32位下针对发生缺页异常的指针位于vmalloc区情况的处理,将主内核页表向当前进程的内核页表同步
{
unsigned long pgd_paddr; // 页全局目录
pmd_t *pmd_k; // 页中间目录
pte_t *pte_k; // 页表项
if (!(address >= VMALLOC_START && address < VMALLOC_END)) // 对地址进行检查
return -1;
pgd_paddr = read_cr3_pa(); // 从CR3中获取最顶级目录页地址(pgd),如果通过current来获取,可能会因为页错误发生在上下文切换时而会出错
pmd_k = vmalloc_sync_one(__va(pgd_paddr), address); // 从主内核页表中,同步vmalloc区发生缺页异常地址对应的页表
if (!pmd_k)
return -1;
if (pmd_large(*pmd_k))
return 0;
pte_k = pte_offset_kernel(pmd_k, address);
if (!pte_present(*pte_k))
return -1;
return 0;
}
/*
* 64-bit:
*
* Handle a fault on the vmalloc area
*/
static noinline int vmalloc_fault(unsigned long address) // 64位下针对发生缺页异常的指针位于vmalloc区情况的处理,将主内核页表向当前进程的内核页表同步
{
pgd_t *pgd, *pgd_ref; // 页全局目录
p4d_t *p4d, *p4d_ref; // 页四级目录
pud_t *pud, *pud_ref; // 页上级目录
pmd_t *pmd, *pmd_ref; // 页中间目录
pte_t *pte, *pte_ref; // 页表项
if (!(address >= VMALLOC_START && address < VMALLOC_END)) // 对地址进行检查
return -1;
pgd = (pgd_t *)__va(read_cr3_pa()) + pgd_index(address); // 得到具体的对应于缺页地址的目录项
pgd_ref = pgd_offset_k(address); // 获取页全局目录地址
if (pgd_none(*pgd_ref))
return -1;
if (pgd_none(*pgd)) {
set_pgd(pgd, *pgd_ref);
arch_flush_lazy_mmu_mode();
} else if (CONFIG_PGTABLE_LEVELS > 4) { //是否启用五级页表
BUG_ON(pgd_page_vaddr(*pgd) != pgd_page_vaddr(*pgd_ref));
}
/* With 4-level paging, copying happens on the p4d level. */
p4d = p4d_offset(pgd, address);
p4d_ref = p4d_offset(pgd_ref, address); // 获取页四级目录地址
if (p4d_none(*p4d_ref))
return -1;
if (p4d_none(*p4d)) {
set_p4d(p4d, *p4d_ref);
arch_flush_lazy_mmu_mode();
} else {
BUG_ON(p4d_pfn(*p4d) != p4d_pfn(*p4d_ref));
}
pud = pud_offset(p4d, address);
pud_ref = pud_offset(p4d_ref, address); // 获取页上级目录地址
if (pud_none(*pud_ref))
return -1;
if (pud_none(*pud) || pud_pfn(*pud) != pud_pfn(*pud_ref))
BUG();
if (pud_large(*pud))
return 0;
pmd = pmd_offset(pud, address); // 获取页中间目录地址
pmd_ref = pmd_offset(pud_ref, address);
if (pmd_none(*pmd_ref))
return -1;
if (pmd_none(*pmd) || pmd_pfn(*pmd) != pmd_pfn(*pmd_ref))
BUG();
if (pmd_large(*pmd))
return 0;
pte_ref = pte_offset_kernel(pmd_ref, address);
if (!pte_present(*pte_ref))
return -1;
pte = pte_offset_kernel(pmd, address); // 获取页表项地址
if (!pte_present(*pte) || pte_pfn(*pte) != pte_pfn(*pte_ref))
BUG();
return 0;
}
2.3. fork 系统调用中的内存管理
mm_struct 结构体是用户进程中的内存描述符结构体:
struct mm_struct {
struct vm_area_struct *mmap; // 指向线性地址对象的链表头部
struct rb_root mm_rb; // 指向线性地址对象的红黑树
u64 vmacache_seqnum;
...
unsigned long mmap_base; // 内存映射区的基地址
unsigned long mmap_legacy_base;
...
pgd_t * pgd; // 页全局目录指针
atomic_t mm_users; // 使用该内存的进程个数
atomic_t mm_count; // mm_struct结构体的引用个数
atomic_long_t nr_ptes; // 页表项总数
#if CONFIG_PGTABLE_LEVELS > 2
atomic_long_t nr_pmds; // 页中间目录总数
#endif
int map_count; // 线性地址个数
spinlock_t page_table_lock; // 保护页表和引用计数的自旋锁
...
unsigned long hiwater_rss; // 进程拥有的最大页表数目
unsigned long hiwater_vm; // 进程线性区的最大页表数目
...
unsigned long start_code, end_code, start_data, end_data; // 维护代码区和数据区的字段
unsigned long start_brk, brk, start_stack; // 维护堆区和栈区的字段
unsigned long arg_start, arg_end, env_start, env_end; // 命令行参数的起始地址和尾地址,环境变量的起始地址和尾地址
unsigned long saved_auxv[AT_VECTOR_SIZE]; // 存储AUXV
...
mm_context_t context; // 内存上下文
...
#ifdef CONFIG_MEMCG
struct task_struct __rcu *owner; // 指向内存描述符所属的进程描述符
#endif
...
};
_do_fork 中调用了 copy_mm 来复制内存,其中主要是 dup_mm 函数对内存信息进行复制:
static int copy_mm(unsigned long clone_flags, struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm;
int retval;
tsk->min_flt = tsk->maj_flt = 0;
tsk->nvcsw = tsk->nivcsw = 0;
...
tsk->mm = NULL;
tsk->active_mm = NULL;
oldmm = current->mm; // 获取当前进程的内存信息
if (!oldmm)
return 0;
vmacache_flush(tsk);
...
retval = -ENOMEM;
mm = dup_mm(tsk); // 复制内存
if (!mm)
goto fail_nomem;
good_mm:
tsk->mm = mm;
tsk->active_mm = mm;
return 0;
...
}
dup_mm 中主要进行了内存的分配和初始化,同时调用了 dup_mmap 进行复制:
static struct mm_struct *dup_mm(struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm = current->mm;
int err;
mm = allocate_mm(); // 分配内存
if (!mm)
goto fail_nomem;
memcpy(mm, oldmm, sizeof(*mm));
if (!mm_init(mm, tsk, mm->user_ns)) // 初始化内存
goto fail_nomem;
err = dup_mmap(mm, oldmm); // 拷贝内存信息
if (err)
goto free_pt;
...
return mm;
...
}
在 dup_mmap 中主要是调用了 copy_page_range,用于对页表的拷贝:
static __latent_entropy int dup_mmap(struct mm_struct *mm,
struct mm_struct *oldmm)
{
struct vm_area_struct *mpnt, *tmp, *prev, **pprev;
struct rb_node **rb_link, *rb_parent;
int retval;
unsigned long charge;
...
mm->total_vm = oldmm->total_vm;
mm->data_vm = oldmm->data_vm;
mm->exec_vm = oldmm->exec_vm;
mm->stack_vm = oldmm->stack_vm;
...
for (mpnt = oldmm->mmap; mpnt; mpnt = mpnt->vm_next) {
struct file *file;
...
if (!(tmp->vm_flags & VM_WIPEONFORK))
retval = copy_page_range(mm, oldmm, mpnt); // 负责页表的拷贝
if (tmp->vm_ops && tmp->vm_ops->open)
tmp->vm_ops->open(tmp);
if (retval)
goto out;
}
...
}
在 copy_page_range 中对页表进行循环拷贝:
int copy_page_range(struct mm_struct *dst_mm, struct mm_struct *src_mm,
struct vm_area_struct *vma)
{
pgd_t *src_pgd, *dst_pgd;
unsigned long next;
unsigned long addr = vma->vm_start;
unsigned long end = vma->vm_end;
unsigned long mmun_start;
unsigned long mmun_end;
bool is_cow;
int ret;
...
is_cow = is_cow_mapping(vma->vm_flags); // 判断父进程的页是否支持写时拷贝
mmun_start = addr;
mmun_end = end;
if (is_cow)
mmu_notifier_invalidate_range_start(src_mm, mmun_start,
mmun_end);
// 循环拷贝页表
ret = 0;
dst_pgd = pgd_offset(dst_mm, addr);
src_pgd = pgd_offset(src_mm, addr);
do {
next = pgd_addr_end(addr, end);
if (pgd_none_or_clear_bad(src_pgd))
continue;
if (unlikely(copy_p4d_range(dst_mm, src_mm, dst_pgd, src_pgd,
vma, addr, next))) {
ret = -ENOMEM;
break;
}
} while (dst_pgd++, src_pgd++, addr = next, addr != end);
if (is_cow)
mmu_notifier_invalidate_range_end(src_mm, mmun_start, mmun_end);
return ret;
}
3. Details(Q&A)
- 创建和初始化内核映射时采用的方式(Lazy/直接)?
-
大概从 Linux-2.6.x 开始,采用了延迟加载的方式。在 Linux-2.4.x 的代码中,
- 对内核页表进行修改后,用户内存如何进行同步(创建/删除/修改)?
- 对调用
vmalloc的当前进程,vmalloc会调用vmalloc_sync_all来同步页表。对于其他进程在内核中访问vmalloc出来的地址,会导致页错误。do_page_fault中会调用:vmalloc_fault,对 32 位机器,会调用vmalloc_sync_one->set_pmd把init_mm的pmd拷贝过来。vfree删除内核页表中的页目录和页表项,也会产生页错误并进行相关处理。
4. References
分析 Linux 内核创建一个新进程的过程 - Mark_Woo
Linux 进程管理(二)-fork - Gityuan
do_fork 浅析 - Halt in Air
Linux 中内核页表是干嘛用的,为什么要有内核页表? - 海枫的回答 - 知乎
Linux 中内核页表是干嘛用的,为什么要有内核页表? - Oliver 的回答 - 知乎
进程如何共享内核页表
内核态不能发生 page fault? - humjb_1983
内核页表和进程页表 - humjb_1983
kernel 3.10 内核源码分析-缺页异常(page fault)处理流程 - humjb_1983
Linux 内存管理 - Gityuan
内核页表和进程页表 - xSun
内核栈与 thread_info 结构详解 - Yungyu
thread_info 与内核栈 stack 关系 - BiscuitOS
第 2 讲 进程控制 - 南京大学张雷
深入理解 linux 内存管理之页表管理 - kernel_dsn
页表们 - Denker