BPF & eBPF
BPF and eBPF.
BPF
BPF (Berkeley Packet Filter) 是类 Unix 系统上数据链路层的一种原始接口,提供原始链路层封包的收发——在内核中将报文复制了一份“镜像”,并用 BPF 指令检查镜像出来的报文并决定报文的去留。1992 年,Steven McCanne 和 Van Jacobson 在 USENIX 上发表了 The BSD Packet Filter: A New Architecture for User-level Packet Capture。在文中,作者描述了他们如何在 Unix 内核实现网络数据包过滤,这种新的技术比当时最先进的数据包过滤技术快 20 倍。BPF 在数据包过滤上引入了两大革新:
- 一个新的虚拟机 (VM) 设计,可以有效地工作在基于寄存器结构的 CPU 之上;
- 应用程序使用缓存只复制与过滤数据包相关的数据,不会复制数据包的所有信息。这样可以最大程度地减少 BPF 处理的数据。
同时,tcpdump 使用的 libpcap 是基于 BPF 的。在使用 tcpdump 或者 libpcap 时传入的 host 192.168.1.1、tcp and port 80 等过滤表达式会被编译成 BPF 指令。可以在 tcpdump 后面增加 -d 参数来查看过滤条件的底层汇编指令:
$ tcpdump -d 'ip and tcp port 8080'
Warning: assuming Ethernet
(000) ldh [12]
(001) jeq #0x800 jt 2 jf 12
(002) ldb [23]
(003) jeq #0x6 jt 4 jf 12
(004) ldh [20]
(005) jset #0x1fff jt 12 jf 6
(006) ldxb 4*([14]&0xf)
(007) ldh [x + 14]
(008) jeq #0x1f90 jt 11 jf 9
(009) ldh [x + 16]
(010) jeq #0x1f90 jt 11 jf 12
(011) ret #262144
(012) ret #0
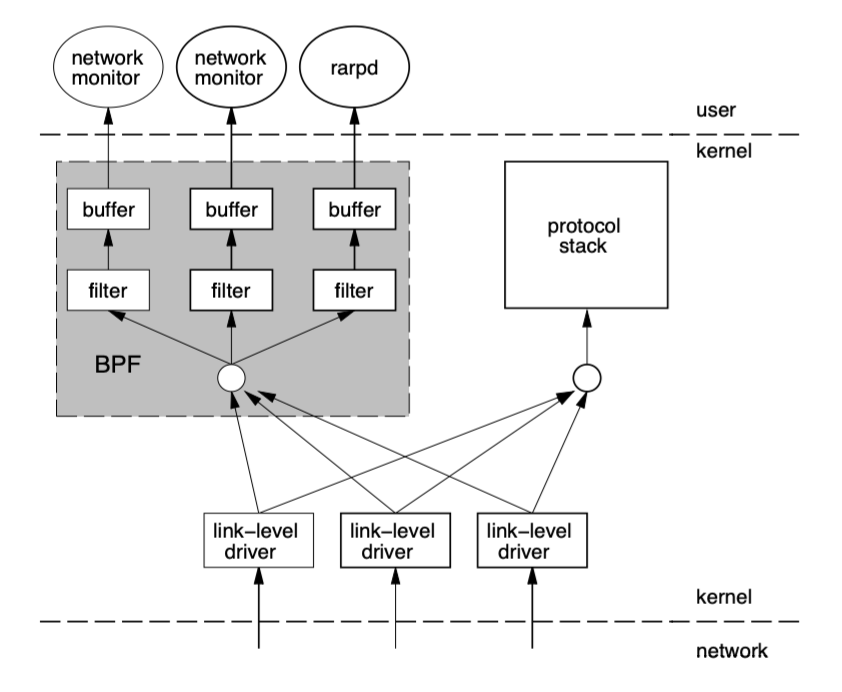
BPF 工作在内核层,其架构图如下:
eBPF
eBPF 是 kernel 3.15 中引入的全新设计,将原先的 BPF 发展成一个指令集更复杂、应用范围更广的“内核虚拟机”。2014 年初,Alexei Starovoitov 实现了 eBPF (extended Berkeley Packet Filter)。经过重新设计,eBPF 演进为一个通用执行引擎,可基于此开发性能分析工具、软件定义网络等诸多场景。eBPF 最早出现在 3.15 内核中,此后原来的 BPF 就被称为经典 BPF,缩写 cBPF (classic BPF),cBPF 现在已经基本废弃。现在,Linux 内核只运行 eBPF,内核会将加载的 cBPF 字节码透明地转换成 eBPF 再执行。
| 维度 | cBPF | eBPF |
|---|---|---|
| 内核版本 | Linux 2.1.75 (1997) | Linux 3.18 (2014) (4.x for kprobe/uprobe/tracepoint/perf-event) |
| 寄存器数目 | 2: A, X |
10: R0–R9, 另外 R10 是一个只读的帧指针 |
| 寄存器宽度 | 32 bit | 64 bit |
| 存储 | 16 个内存位: M[0–15] |
512 字节堆栈,无限制大小的 “map” 存储 |
| 限制的内核调用 | 非常有限,仅限于 JIT 特定 | 有限,通过 bpf_call 指令调用 |
| 目标事件 | 数据包、 seccomp-BPF | 数据包、内核函数、用户函数、跟踪点 PMCs 等 |
Architecture
eBPF 分为用户空间程序和内核程序两部分:
- 用户空间程序负责加载 BPF 字节码至内核,也负责读取内核回传的统计信息或者事件详情;
- 内核中的 BPF 字节码负责在内核中执行特定事件,也会将执行的结果通过 maps 或者 perf-event 事件发送至用户空间;
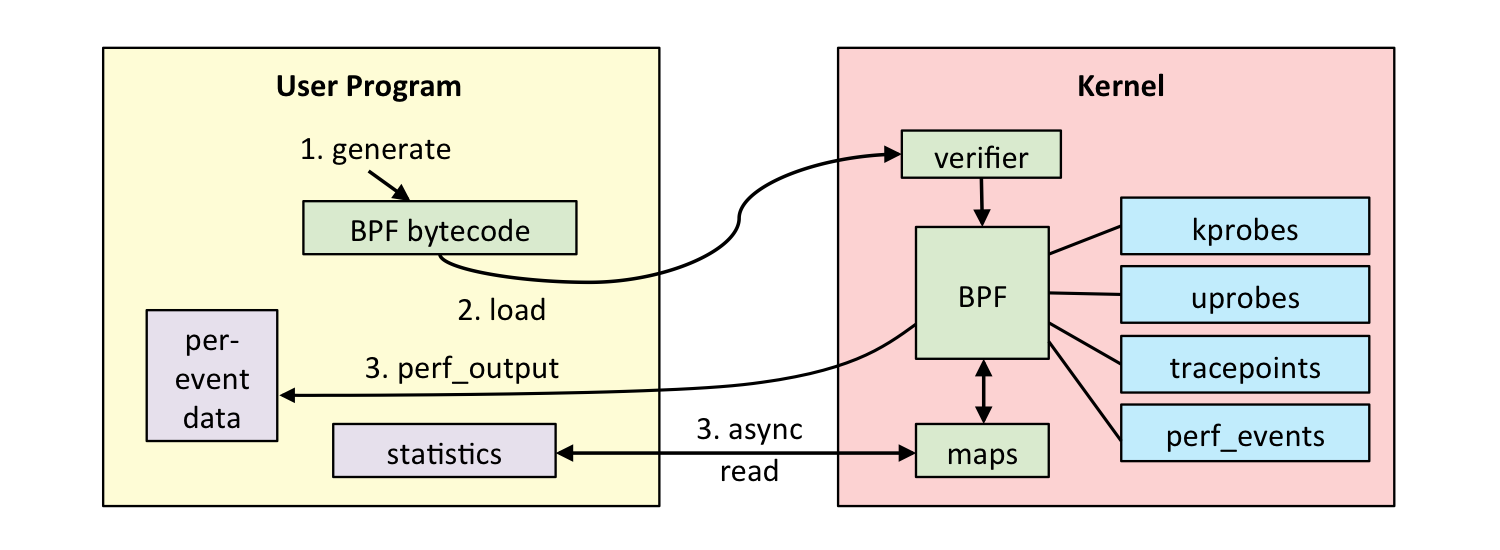
其中用户空间程序与内核 BPF 字节码程序可以使用 map 结构实现双向通信,这为内核中运行的 BPF 字节码程序提供了更加灵活的控制。
Restrictions
eBPF 技术虽然强大,但是为了保证内核的处理安全和及时响应,内核中的 eBPF 技术也存在诸多限制:
- eBPF 程序不能调用任意的内核参数,只限于内核模块中列出的 BPF Helper 函数,函数支持列表也随着内核的演进在不断增加;
- eBPF 程序不允许包含无法到达的指令,防止加载无效代码,延迟程序的终止;
- eBPF 程序中循环次数限制且必须在有限时间内结束,这主要是用来防止在 kprobes 中插入任意的循环,导致锁住整个系统;解决办法包括展开循环,并为需要循环的常见用途添加辅助函数。Linux 5.3 在 BPF 中包含了对有界循环的支持,它有一个可验证的运行时间上限;
- eBPF 堆栈大小被限制在 MAX_BPF_STACK,截止到内核 Linux 5.8 版本,被设置为 512;参见
include/linux/filter.h,这个限制特别是在栈上存储多个字符串缓冲区时:一个char[256]缓冲区会消耗这个栈的一半;
/* BPF program can access up to 512 bytes of stack space. */
#define MAX_BPF_STACK 512
- eBPF 字节码大小最初被限制为 4096 条指令,截止到内核 Linux 5.8 版本, 当前已将放宽至 100 万指令 (
BPF_COMPLEXITY_LIMIT_INSNS),参见:include/linux/bpf.h,对于无权限的 BPF 程序,仍然保留 4096 条限制 (BPF_MAXINSNS);新版本的 eBPF 也支持了多个 eBPF 程序级联调用,虽然传递信息存在某些限制,但是可以通过组合实现更加强大的功能。
#define BPF_COMPLEXITY_LIMIT_INSNS 1000000 /* yes. 1M insns */
Compare to kernel modules
在 Linux 观测方面,eBPF 总是会拿来与 kernel 模块方式进行对比,eBPF 在安全性、入门门槛上比内核模块都有优势,这两点在观测场景下对于用户来讲尤其重要。
| 维度 | Linux 内核模块 | eBPF |
|---|---|---|
| kprobes/tracepoints | 支持 | 支持 |
| 安全性 | 可能引入安全漏洞或导致内核 Panic | 通过验证器进行检查,可以保障内核安全 |
| 内核函数 | 可以调用内核函数 | 只能通过 BPF Helper 函数调用 |
| 编译性 | 需要编译内核 | 不需要编译内核,引入头文件即可 |
| 运行 | 基于相同内核运行 | 基于稳定 ABI 的 BPF 程序可以编译一次,各处运行 |
| 与应用程序交互 | 打印日志或文件 | 通过 perf_event 或 map 结构 |
| 数据结构丰富性 | 一般 | 丰富 |
| 入门门槛 | 高 | 低 |
| 升级 | 需要卸载和加载,可能导致处理流程中断 | 原子替换升级,不会造成处理流程中断 |
| 内核内置 | 视情况而定 | 内核内置支持 |
Code
eBPF 催生了一种全新的软件开发方式。基于这种方式,我们不仅能对内核行为进行编程,甚至还能编写跨多个子系统的处理逻辑,而传统上这些子系统是完全独立、无法用一套逻辑来处理的。
对于大多数开发者而言,更多的是基于 BPF 技术之上编写解决我们日常遇到的各种问题,当前 BCC 和 BPFTrace 两个项目在观测和性能分析上已经有了诸多灵活且功能强大的工具箱,完全可以满足我们日常使用。
- BCC 提供了更高阶的抽象,可以让用户采用 Python、C++ 和 Lua 等高级语言快速开发 BPF 程序;
- BPFTrace 采用类似于 awk 语言快速编写 eBPF 程序;
- 更早期的工具则是使用 C 语言来编写 BPF 程序,使用 LLVM clang 编译成 BPF 代码,这对于普通使用者上手有不少门槛当前仅限于对于 eBPF 技术更加深入的学习场景。
bcc
BCC 是一个 python 库,实现了 map 创建、代码编译、解析、注入等操作,使开发人员只需聚焦于用 C 语言开发要注入的内核代码。BPF: the universal in-kernel virtual machine 介绍了 BPF 从网络子系统中的报文复制功能到内核通用虚拟机 eBPF 的演变过程。
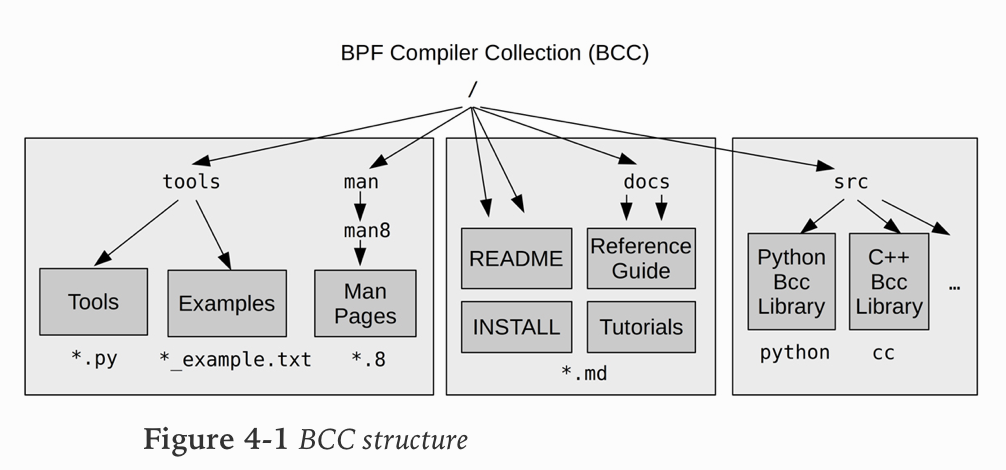
BCC 的编译过程如下:
$ git clone https://github.com/iovisor/bcc.git
$ cd bcc/
$ mkdir build && cd build/
$ cmake ..
$ make
$ sudo make install
$ cmake -DPYTHON_CMD=python3 .. # build python3 binding
$ pushd src/python/
$ make
$ sudo make install
$ popd
使用 BCC 前端绑定语言 Python 编写的 Hello World 版本:
#!/usr/bin/python3
from bcc import BPF
# This may not work for 4.17 on x64, you need replace kprobe__sys_clone with kprobe____x64_sys_clone
prog = """
int kprobe__sys_clone(void *ctx) {
bpf_trace_printk("Hello, World!\\n");
return 0;
}
"""
b = BPF(text=prog, debug=0x04)
b.trace_print()
运行程序时,每当 sys_clone 系统调用时,监控端就会打印 “Hello, World!”,在打印文字前面还包含了调用程序的进程名称,进程 ID 等信息:
$ sudo ./hello.py
Running from kernel directory at: /lib/modules/5.11.0-22-generic/build
clang -cc1 -triple x86_64-unknown-linux-gnu -emit-llvm-bc -emit-llvm-uselists -disable-free -disable-llvm-verifier -discard-value-names -main-file-name main.c -mrelocation-model static -fno-jump-tables -mframe-pointer=none -fmath-errno -fno-rounding-math -mconstructor-aliases -target-cpu x86-64 -tune-cpu generic -fno-split-dwarf-inlining -debug-info-kind=limited -dwarf-version=4 -debugger-tuning=gdb -nostdsysteminc -nobuiltininc -resource-dir lib/clang/12.0.0 -isystem /virtual/lib/clang/include -include ./include/linux/kconfig.h -include /virtual/include/bcc/bpf.h -include /virtual/include/bcc/bpf_workaround.h -include /virtual/include/bcc/helpers.h -isystem /virtual/include -I /home/b3ale/bcc -D __BPF_TRACING__ -I arch/x86/include/ -I arch/x86/include/generated -I include -I arch/x86/include/uapi -I arch/x86/include/generated/uapi -I include/uapi -I include/generated/uapi -D __KERNEL__ -D KBUILD_MODNAME="bcc" -O2 -Wno-deprecated-declarations -Wno-gnu-variable-sized-type-not-at-end -Wno-pragma-once-outside-header -Wno-address-of-packed-member -Wno-unknown-warning-option -Wno-unused-value -Wno-pointer-sign -fdebug-compilation-dir /usr/src/linux-headers-5.11.0-22-generic -ferror-limit 19 -fgnuc-version=4.2.1 -vectorize-loops -vectorize-slp -faddrsig -o main.bc -x c /virtual/main.c
#if defined(BPF_LICENSE)
#error BPF_LICENSE cannot be specified through cflags
#endif
#if !defined(CONFIG_CC_STACKPROTECTOR)
#if defined(CONFIG_CC_STACKPROTECTOR_AUTO) \
|| defined(CONFIG_CC_STACKPROTECTOR_REGULAR) \
|| defined(CONFIG_CC_STACKPROTECTOR_STRONG)
#define CONFIG_CC_STACKPROTECTOR
#endif
#endif
__attribute__((section(".bpf.fn.kprobe__sys_clone")))
int kprobe__sys_clone(void *ctx) {
({ char _fmt[] = "Hello, World!\n"; bpf_trace_printk_(_fmt, sizeof(_fmt)); });
return 0;
}
#include <bcc/footer.h>
b' gnome-terminal--2581 [001] d... 5630.519901: bpf_trace_printk: Hello, World!'
b''
b' gnome-terminal--2581 [001] d... 5630.521618: bpf_trace_printk: Hello, World!'
b''
b' bash-24269 [001] d... 5630.528123: bpf_trace_printk: Hello, World!'
...
bpftrace
BPFTrace 是一个基于 BPF 和 BCC 的应用注入工具,与 BCC 不同的是其提供了更高层次的抽象,可以使用类似 AWK 脚本语言来编写基于 BPF 的跟踪或者性能排查工具,更加易于入门和编写,该工具的主要灵感来自于 Solaris 的 D 语言。BPFTrace 更方便与编写单行的程序。
BPFTrace 使用 LLVM 将脚本编译成 BPF 二进制码,后续使用 BCC 与 Linux 内核进行交互。从功能层面上讲,BPFTrace 的定制性和灵活性不如 BCC,但是比 BCC 工具更加易于理解和使用,降低了 BPF 技术的使用门槛。
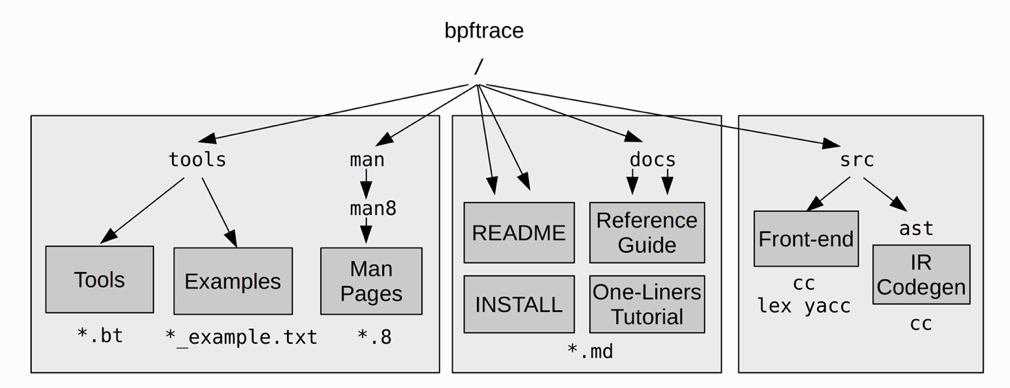
BPFTrace 的编译过程如下:
$ git clone https://github.com/iovisor/bpftrace.git
$ cd bpftrace/
$ mkdir build && cd build/
$ cmake -DCMAKE_BUILD_TYPE=Release ..
$ make
$ sudo make install
使用样例:
$ sudo bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'
Attaching 1 probe...
^C
@[evolution-alarm]: 1
@[rtkit-daemon]: 4
@[gvfs-afc-volume]: 4
@[HangDetector]: 4
@[pipewire-media-]: 6
@[in:imuxsock]: 6
@[rs:main Q:Reg]: 6
@[sudo]: 7
@[irqbalance]: 15
@[JS Helper]: 21
@[dirname]: 38
@[basename]: 38
@[bpftrace]: 42
@[dircolors]: 42
@[dbus-daemon]: 43
@[gmain]: 51
@[ibus-engine-sim]: 57
@[acpid]: 72
@[systemd-journal]: 83
@[pool-gnome-term]: 93
@[lesspipe]: 106
@[Xwayland]: 255
@[systemd]: 291
@[bash]: 601
@[ibus-daemon]: 606
@[vmtoolsd]: 727
@[gnome-terminal-]: 1164
@[gnome-shell]: 3351
@[gdbus]: 3476
References
eBPF - Introduction, Tutorials & Community Resources
eBPF 技术简介 | 云原生社区
Linux 内核功能 eBPF 入门学习(一):BPF、eBPF、BCC 等基本概念@小鸟技术笔记
Linux 内核功能 eBPF 入门学习(二):BCC 中的 eBPF 应用与 bpftrace 等@小鸟技术笔记
Ubuntu 下 bpf 纯 c 程序的编写与运行_金荣的个人技术博客-CSDN 博客
Re: [PATCH 2/2] compiler.h: Include asm/rwonce.h under ARM64 and ALPHA to fix build errors — Linux Network Development
No build scripts available when compiling module outside of Linux source tree - Unix & Linux Stack Exchange
[v1] bpf: fix compilation of samples/bpf/ - Patchwork